

LARGE LANGUAGE MODEL PLAYGROUND MULTI MODELS (PT 5)
Silas Liu - Mar. 31, 2025
Large Language Models
By leveraging the most recent LLMs and topologies, I revamped my PDF processing pipeline, integrating four LLMs running locally on GPU. Each model plays a distinct role in order to maximize efficiency: extracting structured data, augmenting information and synthesizing insights into a coherent technical summary and a visual flowchart diagram.
More than just building a new system, this project reinforces a key principle: LLMs are tools, and understanding their strengths and limitations is crucial for integrating them effectively. Rather than relying on a single generalist model, using specialized models in a coordinated way leads to far better results. Mastering this approach is essential for applying AI in complex, real world scenarios.
Lately, the landscape of LLMs and Generative AI has been flooded with news. With new models and techniques emerging constantly, staying ahead requires more than just following the news, it demands a strategic approach to integrating and applying innovations effectively. More important than simply keeping up with trends is breaking down these advancements, understanding their underlying theory and determining their proper applications. LLMs are merely tools to solve problems, making it essential to define the problem clearly. Choosing the right specialized model for each task is key to maximizing the potential of these technologies.
Models have evolved significantly, and nowadays, we have a vast range of applications, use cases, and model sizes. The techniques within the LLM ecosystem have also advanced, such as Agents implementation and RAG methods.
Given the dynamic environment, I decided to redesign my PDF extraction system, which I initially implemented six months ago. This time, I employed 4 different LLMs, all running locally on a GPU, with each model dedicated to a specific task. This made the new pipeline much more robust, capable of extracting and analyzing technical concepts, diagrams, charts and mathematical formulas. Additionally, I integrated an information augmentation step, using scientific articles from the internet to further enrich the context for the LLMs. At the end of the pipeline, a technical summary of the paper and a flowchart of the proposed content are generated, providing a clear visual roadmap of the article's main propositions.
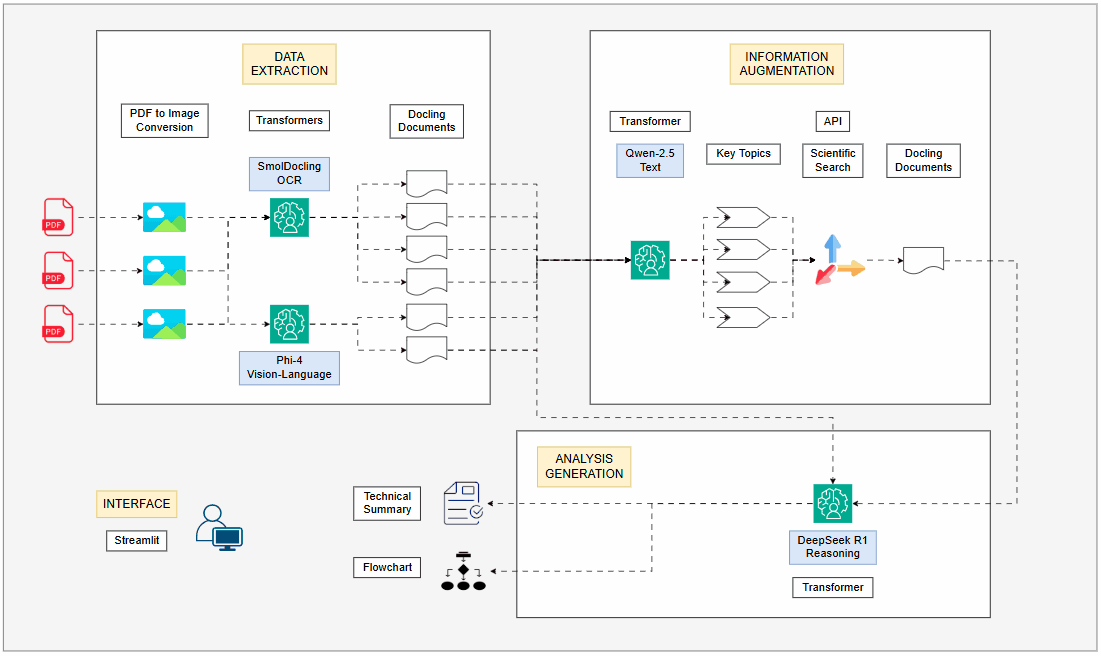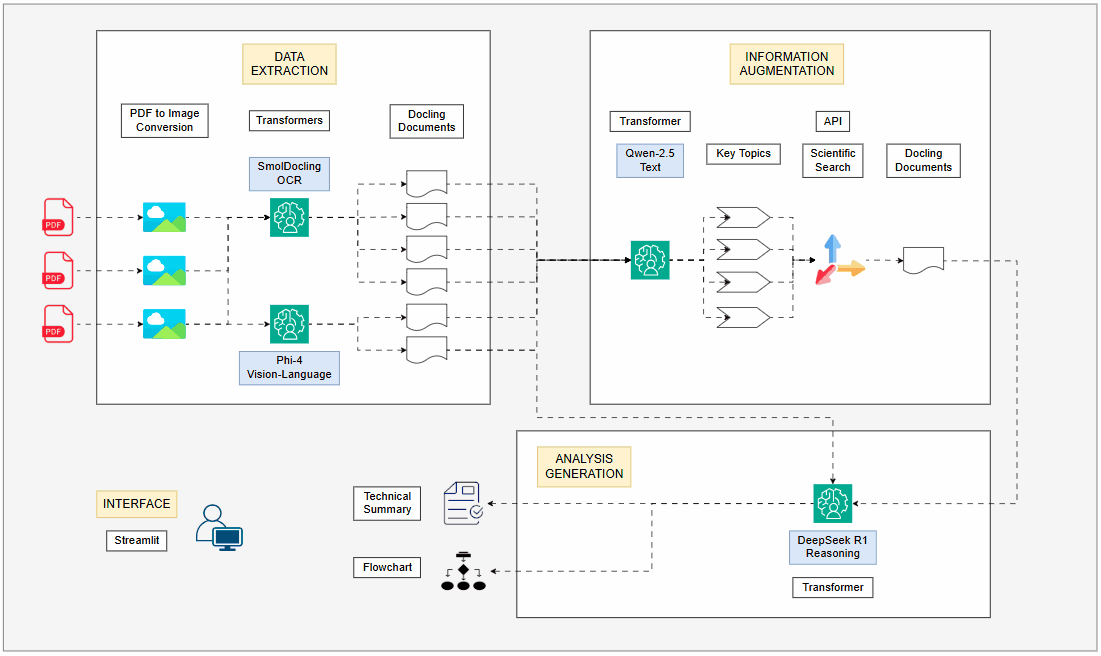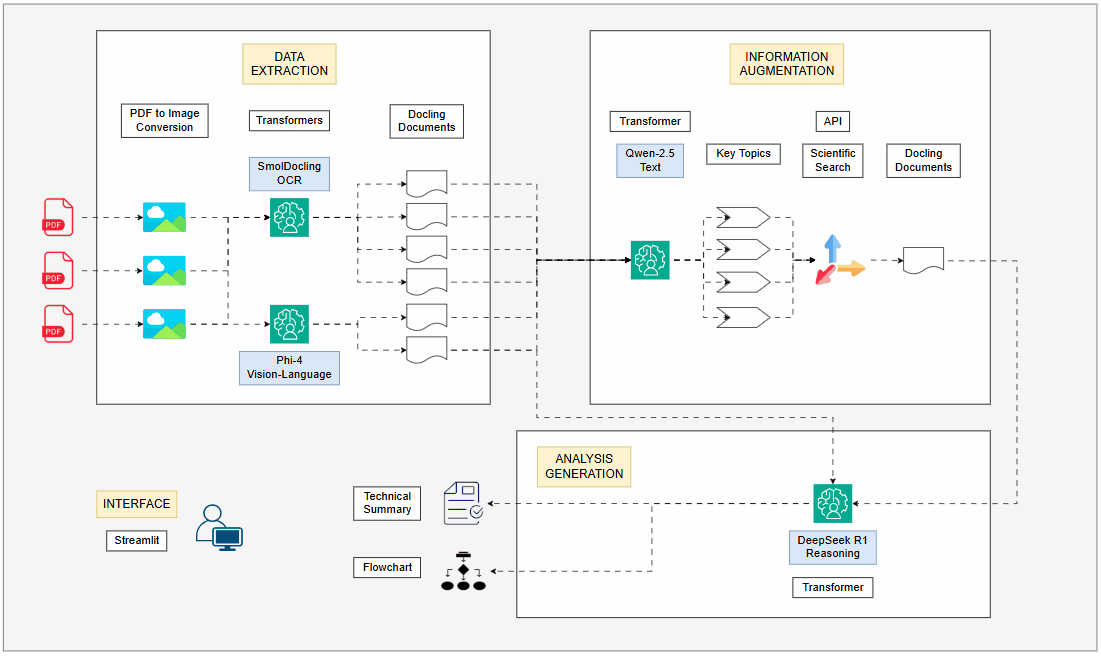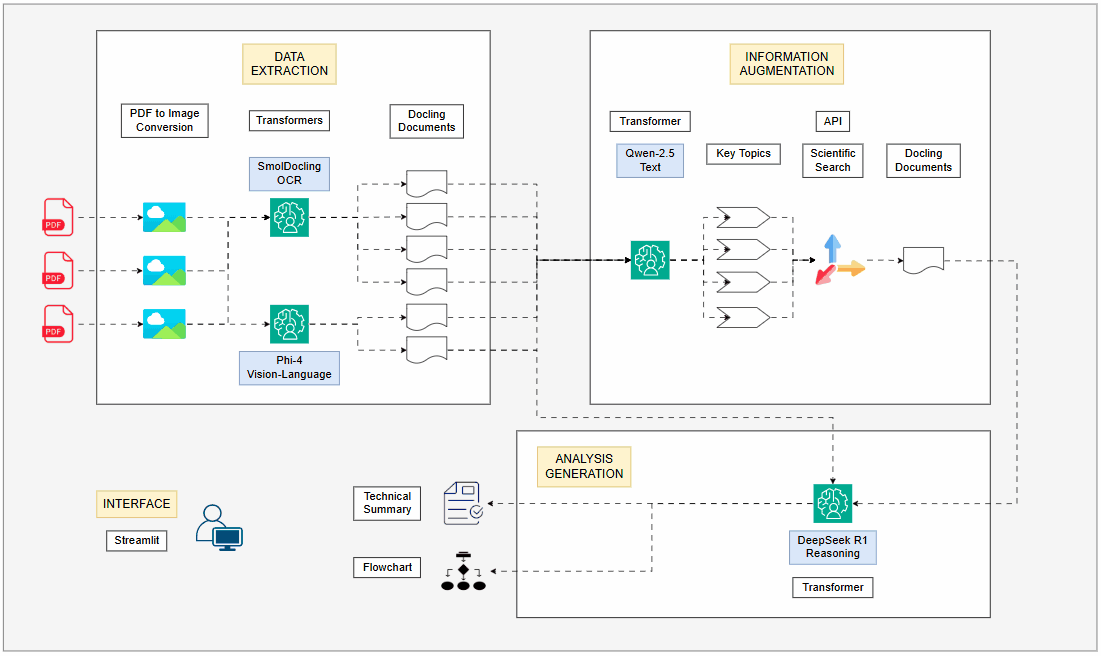
The decision to use four LLMs is based on the premise that each model has specific strengths, making the overall approach far more efficient than using a single general purpose model for everything. AI specialists must understand these differences and implement them correctly according to their use cases.
-
Text and metadata extraction:
Instead of using traditional OCR, I use a LLM specialized in OCR, which can also understand the document's structure. This is crucial for correctly interpreting tables, charts and spatial relationships between elements. -
Image and graph description:
A multimodal model is used to describe images present in the document, transforming visual content into detailed and technical textual descriptions. Many times charts and figures are key to understanding research papers and this step ensures they are integrated into the text for better analysis. -
Information augmentation:
A text based LLM extracts the main topics from the paper, which serve as input for information augmentation. A smaller text model was chosen for this task due to lower memory consumption and faster processing, as the task involves only text. The extracted topics are used in Tavily to find relevant scientific texts. These retrieved documents are then processed and summarized, enriching the article's context with external insights before moving to the next stage of the pipeline. This approach is similar to RAG (Retrieval Augmented Generation), but the augmentation comes from external internet data instead of an internal database. -
Technical summary and flowchart generation:
Generating the technical summary requires a model capable of structuring knowledge logically and coherently. By applying a reasoning LLM, I ensure that the extracted information is well-organized and forms a structured technical summary. Reasoning models are particularly strong in handling technical tasks and logical reasoning, making them well-suited for scientific articles. Additionally, a flowchart representation of the paper's content is generated, offering a structured overview of its concepts and metodologies. This is particularly useful for complex research papers, as it transforms dense technical content into a visually intuitive roadmap, helping the user to quickly grasp the core ideas.
Model | Release Date | Use Case | Key Strength |
|---|---|---|---|
SmolDocling | March 19th, 2025 | OCR | Efficient, SLM for document processing |
All models used were released recently. I chose open-source models that can run locally on a GPU. While having more memory and computational power would allow for larger models and better results, I achieved satisfactory performance with smaller models, each in the range of 7 billion parameters.
-
SmolDocling is a small transformer based multimodal model, designed for efficient document conversion. With a significantly lower parameter count (256 M), it is classified as a Small Language Model (SLM). It is capable of extracting text and metadata from images, representing equations in LaTeX and generating outputs that follow the DoclingDocuments standard.
-
Developed by Microsoft, Phi-4 is a multimodal transformer model that accepts text, images and audio as inputs. Here, I am using only its image processing capabilities. Trained using techniques such as supervised fine-tuning, direct preference optimization and RLHF (Reinforcement Learning from Human Feedback), Phi-4 has outperformed models like Gemini 2.0 Flash in vision-language tasks.
-
Developed by Alibaba Cloud, Qwen 2.5 is a multimodal transformer model known for its strong instruction following abilities. However, in my pipeline, I use only the text processing version to optimize memory usage and processing time.
-
DeepSeek R1, developed by DeepSeek AI, is a reasoning focused transformer model that gained attention upon release for outperforming OpenAI o1 model in several benchmarks. It introduced multiple innovations in its architecture while remaining open-source. DeepSeek R1 set a new standard for performance and cost-efficiency in LLMs by being trained on less powerful hardware, undergoing extensive hardware level optimizations and leveraging a customized operating system. It also implements techniques such as Mixture of Experts (MoE) and reinforcement learning (RL). Additionally, distilled versions of the model were developed, featuring fewer parameters and leveraging architectures like Qwen and Llama.

The figure above illustrates an example of a processed research paper. Since all models run locally, there are no token usage costs and data security is ensured, as all processing happens on my machine. This system will help me stay up to date with new research papers, making it easier to analyze and extract insights from the latest scientific advancements.
Building this system was a highly engaging challenge and I had to address additional complexities such as asynchronous task orchestration and optimized GPU memory management, given that my GPU had to run four different LLMs.
Looking ahead, I plan to keep expanding my LLM Playground, continuously testing and integrating new AI techniques to enhance various applications and my knowledge.