

LARGE LANGUAGE MODEL PLAYGROUND MCP (PT 6)
Silas Liu - Apr. 11, 2025
Updated: Apr. 15, 2025
Large Language Models,
Model Context Protocol
To explore new concepts of the LLM ecosystem, I built E.V.A., a local assistant powered by MCP (Model Context Protocol). With MCP the LLM can interact with tools exposed on the computer, like moving the mouse, clicking, typing or taking screenshots, all through a unified standard interface.
By combining MCP with voice input/output and local models for STT/TTS, E.V.A. becomes a real-time autonomous agent capable of navigating software and the web like a human user.
This setup shows how standardizing tool access can unlock truly interactive LLM systems: modular, extensible, production-ready autonomy.
With the growing popularity of agents and the increasing need to integrate tools into LLM-based systems, the concept of MCP has also been gaining traction. Introduced by Anthropic in November 2024, MCP stands for Model Context Protocol, and is a proposal to standardize how LLMs interact with external tools. The vision is that, in the future, we will be able to plug any tool into any LLM using MCP as a universal compatibility layer.
When we talk about LLM agents, we refer to operational pipelines where language models interact with the environment through tools. These tools can represent nearly any type of external interaction such as: running code, controlling devices, accessing APIs, browsing the internet, retrieving data from databases, etc. This allows the model to go beyond being just a text generator and become an autonomous actor.
Currently, each tool typically requires its own custom implementation, including wrappers for inputs and outputs. MCP aims to standardize tool interfaces, introducing a client-server architecture reminiscent of the modern web. An MCP server exposes a set of tools, which the LLM can access. During its reasoning process, the model decides which tool to invoke and uses the client to execute and retrieve the result.
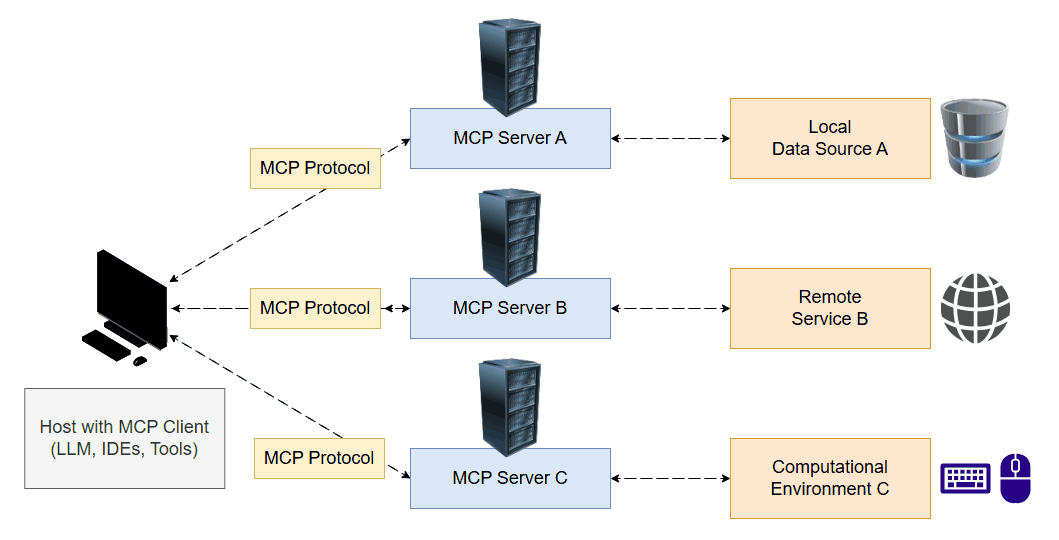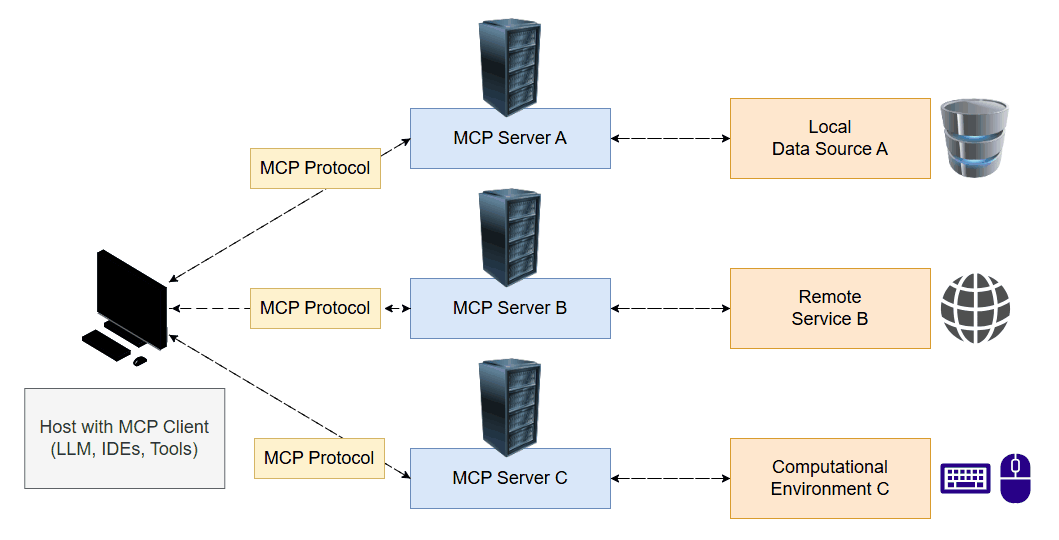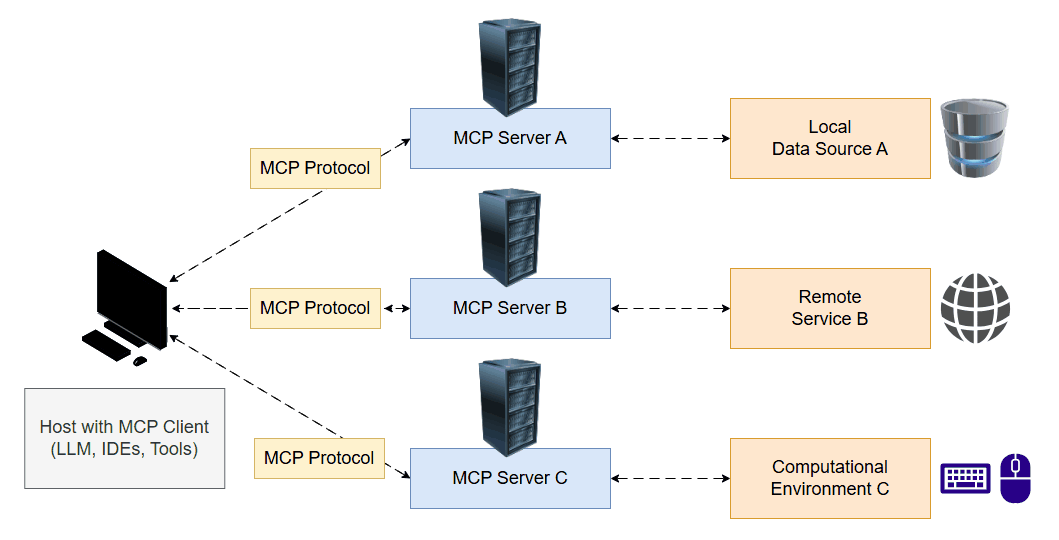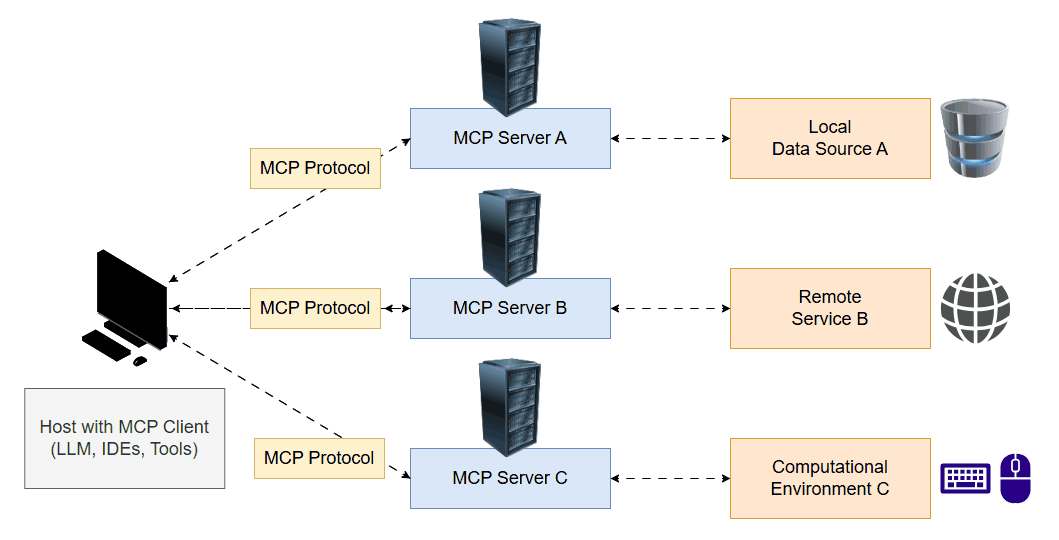
To explore this concept, I developed a project called E.V.A. (Enhanced Virtual Assistant). The system includes both an MCP server and client, offering tools that interact directly with my computer. This allows the LLM to take screenshots, view the screen, move the mouse, click it and type text. This opens up a wide range of possibilities where the model can act as a real user in a computational environment.
To guide the LLM's reasoning and tool usage, I implemented the ReAct pattern (Reasoning + Acting) which is widely used in agentic frameworks. ReAct allows the model to think step by step and interleave reasoning with actions, rather than just issuing a single command. This pattern is especially useful for complex tasks that require multiple tool calls, as it makes the LLM more robust and interpreatable by encouraging deliberate decision-making before each action.

In addition to MCP, I integrated voice input and output. For input, I used a transformer-based STT (speech-to-text) model, and for output a TTS (text-to-speech) model. The central LLM receives voice commands and decides, in real time, which tools to use after each iteration.
MCP adds flexibility to the system, making it easy to plug in new tools and functionalities without modifying the core logic. While it still presents challenges, such as versioning, data privacy and security, like any new technology, is in a maturation process and has the potential to become a reliable and scalable protocol for production systems using LLMs.
Below are video examples showcasing my implementation and use cases. With the time I will be adding more videos! 🙂
Use Case: Google Maps
In this use case I ask it to show me the Statue of Liberty on Google Maps, and it is capable of reasoning to open the browser, click the search button, enter the terms to search, click on the right option and finally give me the response answer.
Use Case: Calendar / Wikipedia
Here I ask it to see what meetings I have, search on their topics and give me a summary. The LLM then reasons to open my Calendar, read the screen, search the topic with Wikipedia API and make a summary of received content.
The original Anthropic's code was designed to run with their ecosystem, including Claude as the model base and integration to their Claude Desktop app. However it is easy to understand and, in my case, I adapted it to run without Claude Desktop and with my own LLM models.
To learn more you can access Anthropic's announcement: