

LLM IMPROVEMENT WITH RAG IN KNOWLEDGE-GRAPH
Silas Liu - Dec. 28, 2023
Large Language Models, Graphs
Recently, Large Language Models (LLM) have been evolving at a breathtaking pace, bringing along incredible and innovative applications. In conjunction with everything these models have to offer, I have been delving into the most advanced and recent modeling techniques in data science.
I present here a project born out of my studies and investment, which integrates NoSQL databases into Knowledge Graphs, employing Retrieval Augmented Genration (RAG) techniques.
This results in a model that overcomes two major issues in current LLM models: susceptibility to hallucinations in responses and limitations in training data. I provide a brief illustration of the key concepts and their applications.
Over the past few months, I have been investing my free time in a personal project that quickly expanded in all aspects: implementation, complexity and applications. This project addresses advanced and state-of-the-art techniques that are continuously evolving, thanks to current Large-Language Models (LLMs). I continue to learn and refine my skills in these fascinating fields of data science, seeking incresingly innovative solutions.
The core of the project involves representing data through a knowledge-graph, a NoSQL structure, different from conventional tabels. Its representation can be compared to a spider's web, an intricate fabric of information and knowledge.

It is widely know that current LLM models suffer from two drawbacks: their ease of hallucination and generating created responses to the user; and knowledge limitations. Their responses are based on information and databases restricted to their training dates.
These two issues can be addressed applying advanced Retrieval Augmented Generation (RAG) techniques from a Knowledge Graph to an LLM model. This innovative approach allows the system to retrieve relevant information by combining assertive data retrieval with responsive generation.

Through an intuitive interface, the user has quick and easy access to an LLM model that functions as an intelligent assistant. Unlike conventional implementations, this chatbot can interpret questions, analyze specific data sources, and generate responses based on unstructured data.
I begin by illustrating the application of the model being fed with updated data from the 2023 Oscars, without the need to retrain the entire model on new data.
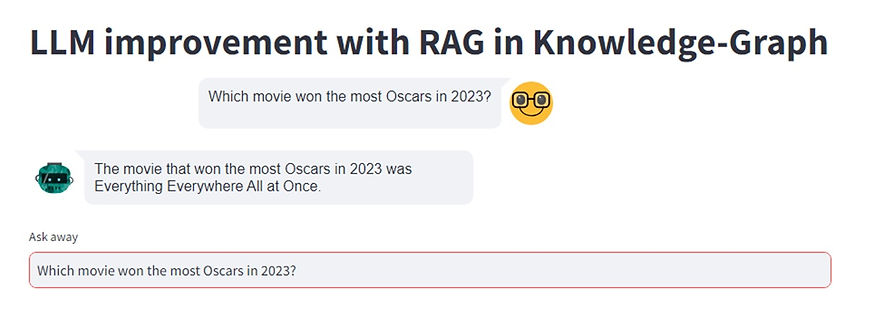
Similar to current LLM models, our model can intuitively and directly deduce the conversation context from the conversation history.
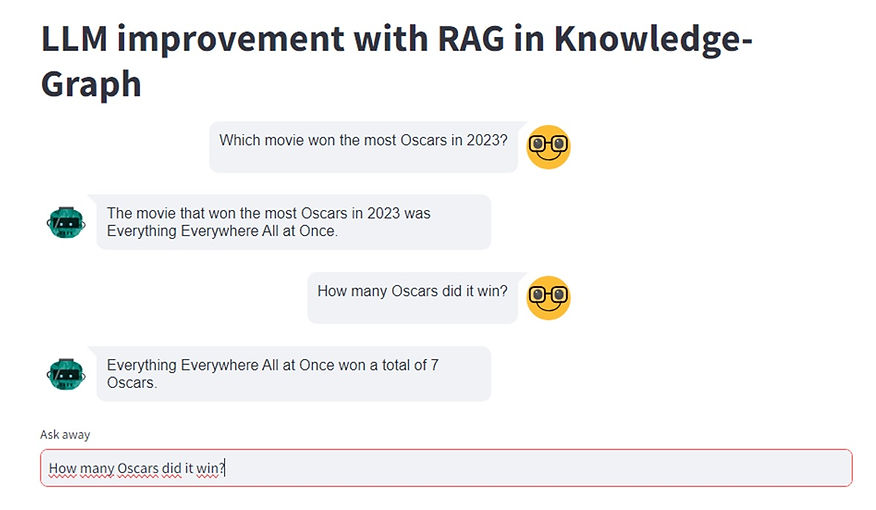
Now comes the best part. In the next conversation, I make three questions, demonstrating that it is possible to delve deeper and construct more complex questions, requiring interpretation, analysis and correlation of data for the correct answers.

This personal project has been an incredible journey, exploring new tools and possibilities involving machine learning and data science. It is still in development and refinement phase and may absorb new functionalities over time. The encouragement and expertise of the Peers Data Science team played an important role in the development of this project.