

LLM PLAYGROUND PHOTO ALBUM
(PT 8)
Silas Liu - Oct. 16, 2025
Large Language Models,
Graphs, Cloud, Webpage
This project shows how language models can act as reasoning layers within a data systems, transforming raw structure into meaningful interaction. By combining a graph database for relationships, embeddings for semantic similarity, and LLMs for intent translation and narrative generation, the architecture demonstrates how logic and language can coexist in a unified retrieval and storytelling pipeline. Each component plays a precise role, creating a balanced integration between deterministic data handling and semantic reasoning.
At a broader level, it represents a fusion between engineering precision and creative expression. Using my own photography as the foundation, the system transforms genuine visual content into interactive, language-driven exploration. More than a technical experiment, it illustrates how LLMs can complement human creativity, not by generating art, but by organizing, interpreting and giving narrative structure to it.
With the recent evolution of multimodal systems and the increasing integration of LLMs into everyday applications, new possibilities have emerged for combining them as tools for structured data. Beyond text analysis or document processing, LLMs can now operate as reasoning components within larger architectures, orchestrating logic, retrieval and content synthesis. Motivated by this shift, I decided to build a personal photo webpage that explores how LLMs can enhance retrieval and storytelling, not as the core engine, but as specialized tools working alongside traditional systems. The project also connects with one of my personal interests: photography, and all images displayed are original photos taken by me, without any AI-generated content.
The project architecture follows a layered design, separating the user interface, intelligent retrieval and narrative generation. The frontend was developed in Javascript and provides a responsive interface for browsing and filtering photos. The backend, implemented in Python, manages communication between the interface, the graph database, and the LLM components. Metadata is stored in Neo4j, where each photo is represented as a node within a connected structure. Images are hosted in Google Cloud Storage, ensuring scalability and fast access across the system.
The figure below illustrates the complete architecture. showing how the frontend, backend, graph database, LLMs and cloud storage interact across three layers. Dashed lines represent LLM-assisted operations: query generation, embedding synthesis, narrative creation, which are integrated as modular calls. By isolating these calls and validating every output, the system maintains deterministic behavior while still leveraging the expressive power of LLMs.
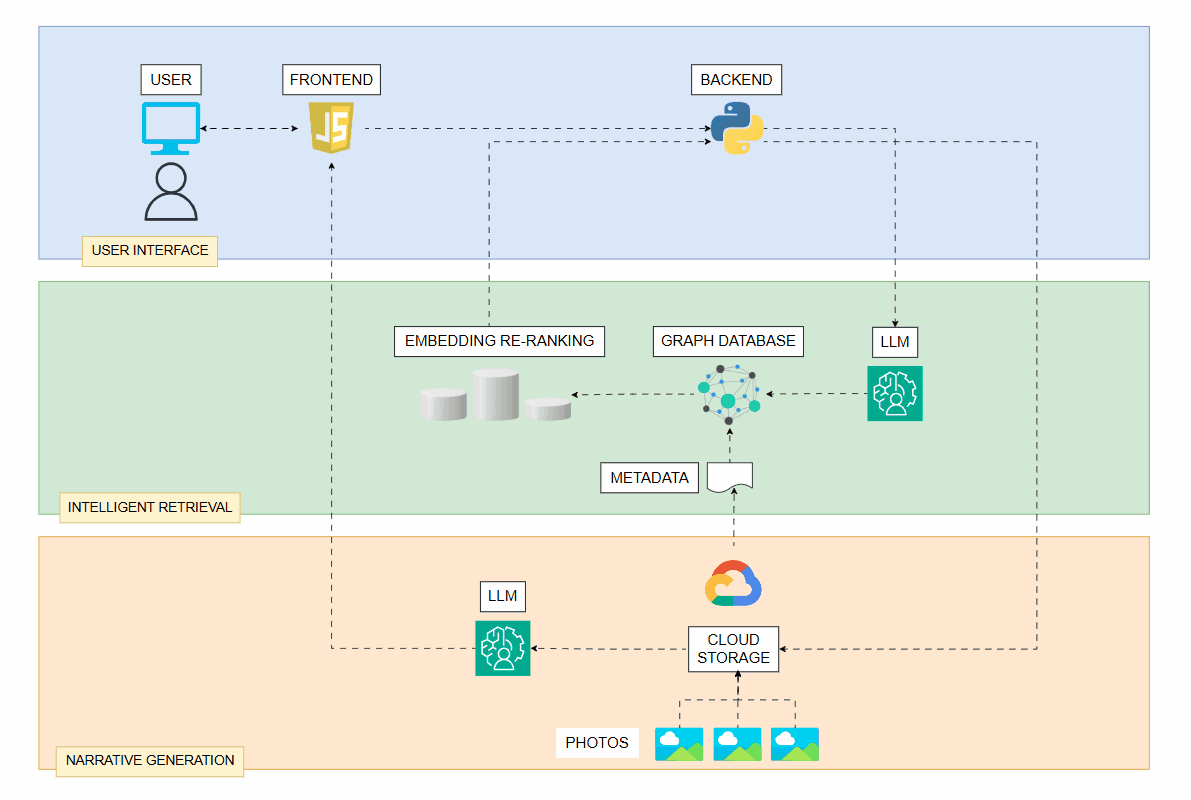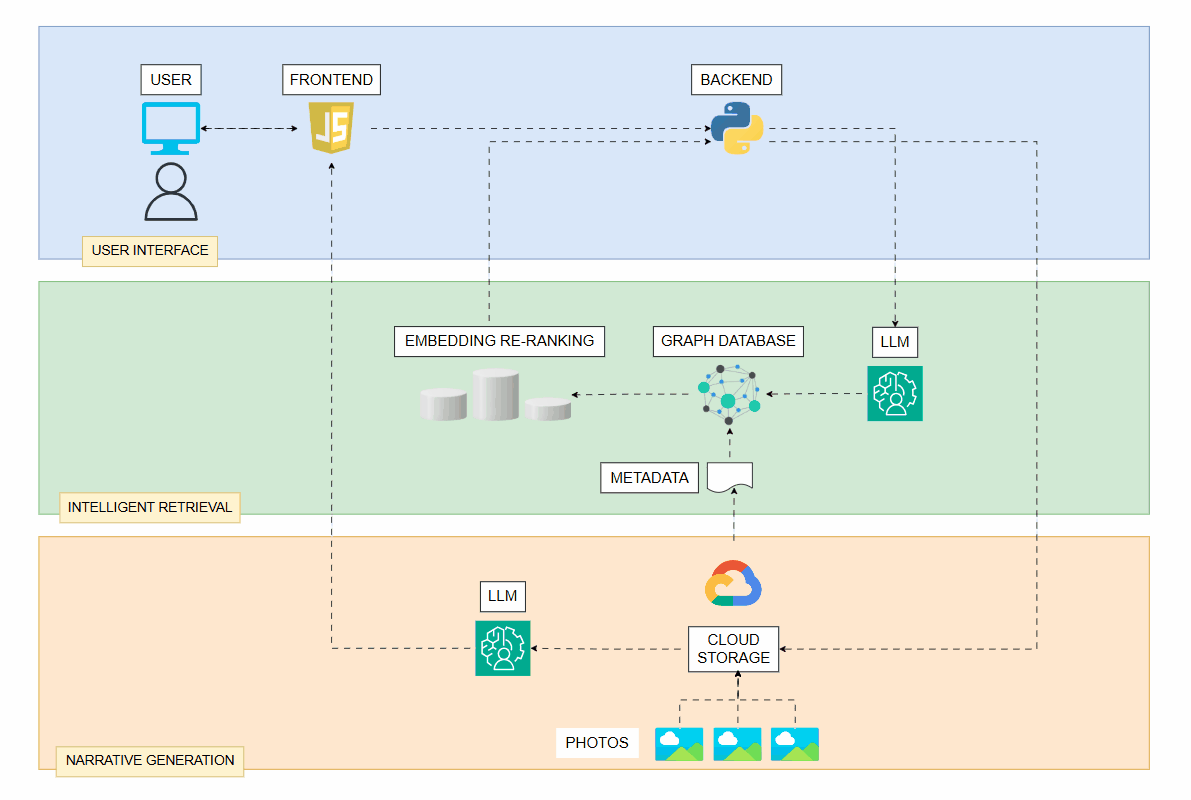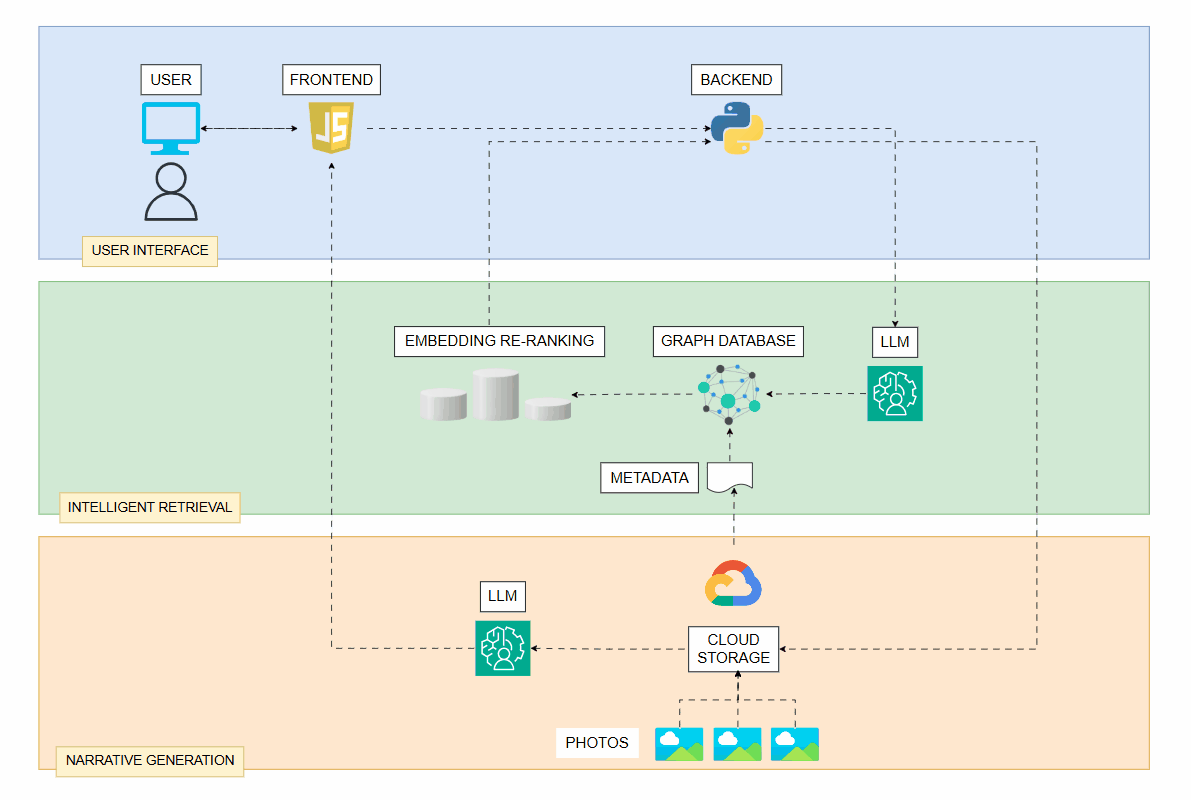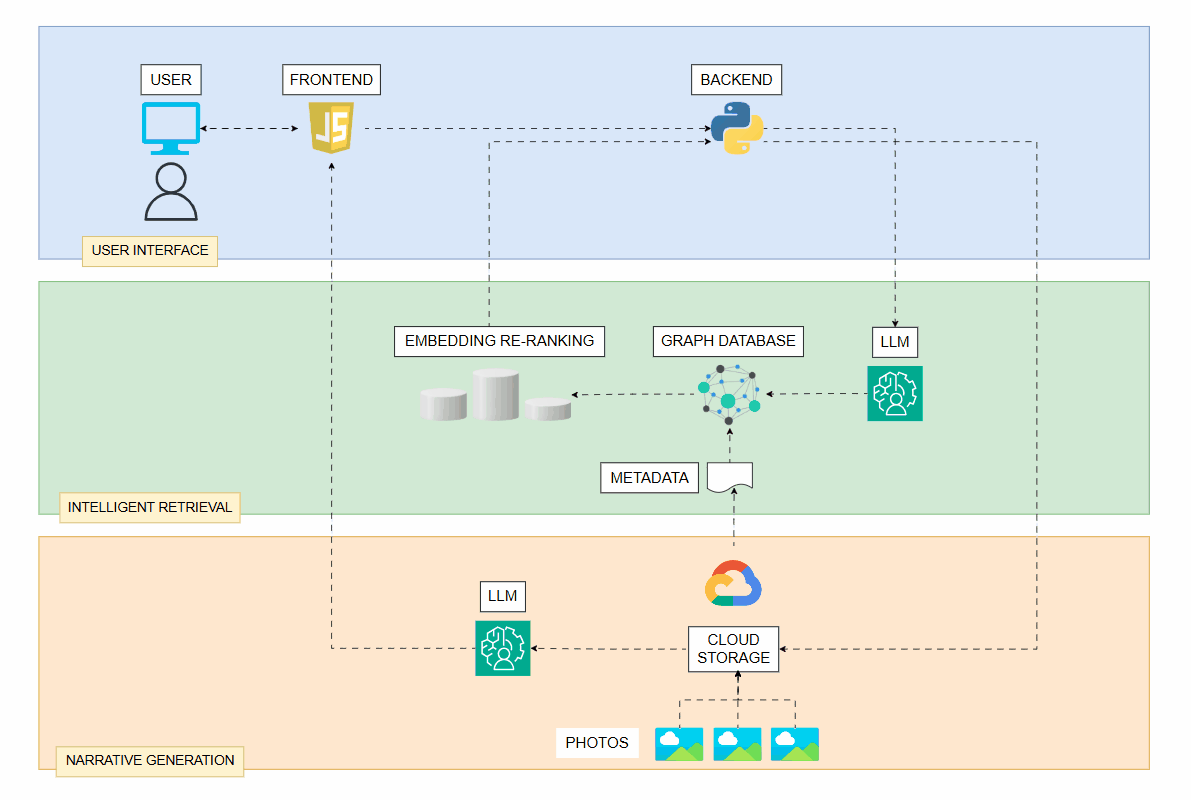
The retrieval process is divided into two stages. The first is a graph-based filtering step, where Neo4j executes Cypher queries to retrieve candidate photos based on structured metadata. Instead of manually defining every filter condition, the backend delegates part of this task to a LLM, which generates the query clauses dynamically. The model receives the user's intent in natural language and produces a safe, parameterized Cypher filter. This approach allows for flexible search expressions while maintaining strict control through input validation.
After retrieving the initial candidates, a second step applies an embedding-based re-ranking. Each photo has a precomputed embedding derived from its metadata, captions and image descriptions. The LLM generates a concise embedding sentence that captures the semantic intent of the query. The sentence is then embedded and compared with the stored vectors. The result is a refined ranking that aligns more closely with user expectations, combining the precision of graph filtering with the flexibility of vector similarity.
Beyond retrieval, the system also focuses on narrative generation. Once the final set of photos is selected, another LLM composes short textual descriptions and group titles, organizing the photos into coherent visual stories. These narratives give context to the selection, transforming simple photo collections into structured albums. Each description is grounded in metadata, ensuring that the generated text remains faithful to the original data while providing a natural, human-like explanation of the group's theme. This design allows the system to act as a storytelling assistant, narrating real photos instead of inventing them, a balance between automation and authenticity.
This project reinforces the idea that LLMs should not replace traditional data systems, but rather complement them where semantics and reasoning add value. The combination of graph database for structured relationships, embeddings for similarity and LLMs for intent translation creates a robust hybrid retrieval architecture. Each component operates within clear boundaries: the database handles structure, embeddings handle proximity, and the LLM bridges language and logic.
In essence, this project blends engineering and creativity, a hybrid of data architecture and artistic expression. It demonstrates how language models can enrich human-centered systems without overshadowing them, providing reasoning, structure and narrative around genuine visual content. The webpage stands as a personal experiment in applying LLMs to storytelling through photography, and can be accessed for exploration at:
https://silas-photography-with-ai.onrender.com/
You can also try it directly below.