

COLONY SIMULATOR
Silas Liu - February 18, 2026
Complex Systems, Reinforcement Learning,
Large Language Models
Complex systems thrive on the tension between individual autonomy and collective regulation. In this project, I engineered a Hierarchical Complex Adaptive System (HCAS) that mimics biological structures by splitting intelligence into two distinct layers: a Micro-level of autonomous units and a Macro-level strategic "Governor". This architecture allows a colony of units to navigate unpredictable environments and survive non-linear shocks that would break traditional, static systems.
By combining Goal-Conditioned Reinforcement Learning (GCRL) for tactical "instincts" with a Large Language Model (LLM) for homeostatic regulation, the system achieves a form of hybrid intelligence. The results demonstrate that while individual parts handle the "noise" of local interaction, the LLM provides the "signal" for long-horizon survival. This project serves as a blueprint for building robust, multi-unit ecosystems capable of strategic adaptation without the need for constant retraining.
Complex Systems
A complex system is a large network of interconnected, interacting components, often called agents, that collectively produce emergent, unpredictable and nonlinear behaviors not displayed by individual parts. These systems are characterized by adaptation, self-organization and feedback loops, where the whole is greater than the sum of its parts.
Some examples are the human immune system, living ecosystems, world economies, weather behavior. A perfect example is an ant colony. Single ants act on local clues such as smells, touch, immediate goals. No single ant has the overall view, yet, the colony displays a collective intelligence that allows it to bridge gaps, defend against invaders and optimize food retrieval, leading to sophisticated outcomes.
In this project, I built a Hierarchical Complex Adaptive System (HCAS) that splits intelligence into two distinct layers, mimicking the biological structure of life:
-
Micro-Level (The Agents): Using Reinforcement Learning (RL), I trained individual ants to develop their own "instincts". One group learned the art of food retrieval (Foragers), while another learned the grit of nest defense (Guardians).
-
Macro-Level (The Hive Mind): Here I introduced a Large Language Model (LLM) as the colony's "governor". It does not micro-manage every step. Instead, it observes the big picture: total food, nest HP and threat levels, and makes strategic decisions about the distribution of tasks.

The Micro-Layer: Goal-Conditioned Reinforcement Learning (GCRL)
To implement the "instinct" of the agents, I designed a neural architecture capable of processing local spatial information and converting it into precise tactical actions. The Micro-level is where the actual labor occurs through specialized neural networks.
Neural Topology & Input Space
Both the Forager and the Guardian utilize a mirrored neural topology: a deep feed-forward structure with two hidden layers of 256 nodes each. This width allows the agents to capture the complex, non-linear relationships required for navigation and combat within a grid-based environment.
Each agent processes a state vector of 41 features. This input space is a fusion of several different data types:
-
Sensor Data: Detection of pheromone trails or food scent gradients.
-
Internal State: Telemetry such as current Health Points (HP) or food carriage.
-
Local Occupancy Grid: A 5x5 "Tactile Vision" window. This provides the agent with immediate spatial awareness of its surroundings, detecting walls, food or enemies in its direct vicinity.

Task-Specific Goal Conditioning
The Goal-Conditioned Reinforcement Learning (GCRL) was used to manage the behavioral complexity within each role. By feeding a Goal Vector g into the policy π(a|s,g) , the agent learns to prioritize different sub-behaviors based on the immediate context.
The forager's "intelligence" is a sequence of four distinct internal goals:
-
Exploration: Stochastic movement to map unknown territory.
-
Pheromone Tracking: Following chemical signals left by successful foragers.
-
Scent Gradient: Honing in on the source of food once a scent is detected.
-
Homing: Returning to the nest while depositing pheromones to reinforce the path for others.
Label:
Blue: Nest
Yellow: Food and food scent
White: Ant
Red: Ant carrying food
Green: Pheromone trail
The guardian's policy is focused on spatial control and collective defense:
-
Patrol: Maintaining a perimeter around the nest coordinates.
-
Pursuit: Identifying a threat and maintaining proximity to intercept it.
-
Collective Engagement: A strategic trigger that initiates an attack only when in the company of other guardians, preventing "suicide missions" and favoring swarm-based combat.
Label:
Blue: Nest
White Gradient: Ant's HP
Purple Gradient: Threat's HP
By segregating these instincts into two highly specialized GCRL networks, the colony possesses a robust library of behaviors. The challenge then shifts from how an ant performs a task to how many ants should be performing each task at any given moment, a decision-making process reserved for the Macro-level.
The Macro-Layer: The Homeostatic Regulator (LLM)
While the individual RL agents are immersed in the "noise" of the environment, processing 41 local sensors to navigate and survive, the LLM Governor operates at a higher level of abstraction. It receives a curated stream of global statistics to act as the colony's strategic brain, balancing the scales between resource acquisition and survival.
Macro-Telemetry and Temporal Feedback
To enable a sense of "memory" and trend analysis, I provide the model with two windows of stats. This temporal context includes:
-
State Snapshots: Current alive population, total nest food and the existing ratio of foragers.
-
Dynamic Deltas: The change in nest food (accounting for consumption and decay), the number of deaths since the previous window and the count of enemies neutralized.
By comparing these two windows, the LLM functions similarly to a PID (Proportional-Integral-Derivative) Controller. It doesn't just react to the current state; it senses the momentum of the system. If food is dropping faster than the previous window despite a higher forager ratio, the model can infer a scarcity crisis or a logistical bottleneck and adjust accordingly.
Emergence vs. Regulation
In the language of Complexity Science, this architecture creates a tension between Emergence and Regulation.
The agents provide the emergence: the complex, unpredictable patterns of pheromone trails and combat maneuvers that each agent decides. Left alone, this emergence can be fragile, a colony might over-forage and leave the nest defenseless against a sudden surge of enemies.
The LLM provides the regulation. It acts as a Homeostatic Regulator, much like the hypothalamus in a human brain that regulates body temperature. It doesn't tell the cells (the ants) how to do their jobs, it simply shifts the environment's hormonal balance (the task ratio) to keep the colony within its survival parameters.
This hierarchical control ensures that the colony can pivot its entire strategy without needing to retrain the underlying neural networks. It is the bridge between the fast, instinctive reactions of RL and the slow, deliberate reasoning of Large Language Models.

Experiments and Comparative Analysis
To validate the effectiveness of the LLM Governor, I conducted a series of experiments comparing the adaptive colony against a Baseline system where the task distribution was fixed at 50% Foragers and 50% Guardians. The goal was to observe how each system handled environmental equilibrium and sudden, non-linear shocks.
Scenario 1: The Default Environment
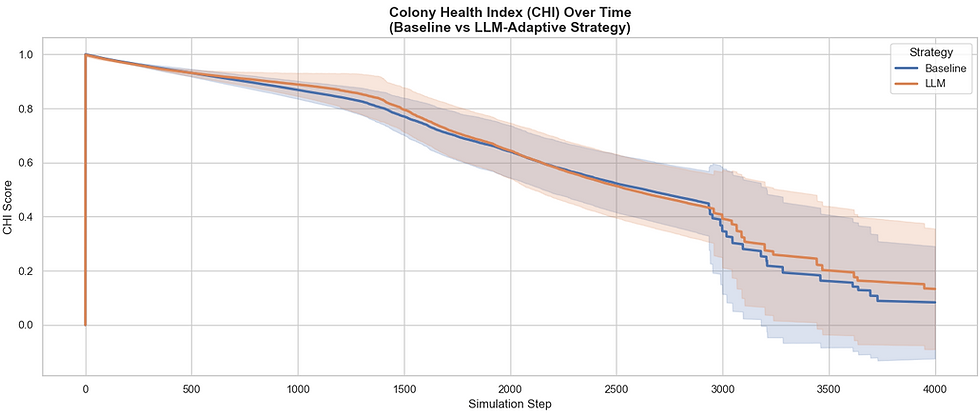
In this scenario, we observe the system in a stationary state with an initial low-level threat. We see a fundamental clash between the Baseline's safe heuristic and the LLM's aggressive investment strategy. Both the CHI chart and the Pareto Frontier provide the high-level "scorecard" for the simulation.
The Colony Health Index (CHI) is a composite score derived from population sustainability and resource accumulation. As shown in the CHI graph, the LLM strategy establishes a superior CHI from the very first steps and maintains a widening advantage throught the simulation.
The Pareto Frontier confirms this strategy pivot. Looking at the Mean Indicators:
-
The Baseline Mean (Blue Cross): With fewer population (~88 ants) and lower food security (~51 units) it is located in the lower left side.
-
The LLM Mean (Red Cross): With a higher population (~97 ants) and a massive increase in resource security (~719 units) it is located far to the upper right side.
The LLM dominates in both dimensions simultaneously: more survivors and dramatically more food, suggesting adaptive governance is globally superior under low threat, rather than simply trading one objective for another.


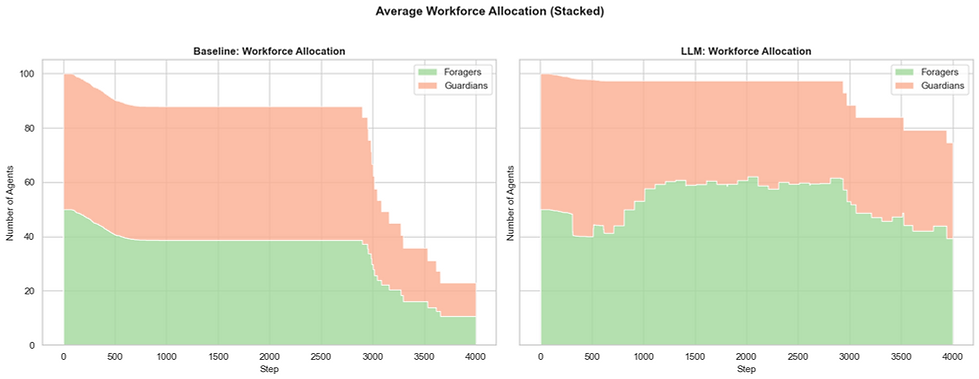
To understand how the LLM achieves that resource surplus, we look at System Dynamics and the Average Workforce Allocation.
The Workforce Allocation chart reveals the LLM's "Brain" in action. Unlike the Baseline's rigid 50/50 split, the LLM immediately expands the Forager proportion to ~60-65% from step 0, recognizing low threat early and prioritizing resource acquisition. The Guardian allocation stabilizes at ~35-40% as a maintained defensive buffer, never spiking, never collapsing to zero.
This is mirrored in the System Dynamics charts. Interestingly, the LLM's per-step efficiency is actually lower than the Baseline's peak, but it sustains food collection for the entire simulation. The Baseline's intake collapses to zero when nest food is exhausted at ~step 3,000, while the LLM continues collecting. Duration beats peak rate.

Finally, the Threat Analysis and Death Spiral graphics show the ultimate consequence of these strategic choices.
Looking at the Threat Analysis, the Baseline neutralizes all 5 enemies. The LLM averages only 1.5 kills, not because it fails, but because it deliberately avoids attrition. With fewer Guardians deployed, the colony opts for perimeter containment rather than active combat, freeing the majority of agents to forage. This emergent 'threat avoidance' strategy is never explicitly programmed, it arises from the Governor optimizing the food/population balance.
This proactive stance prevents the catastrophic Death Spiral seen in the Baseline. In the Baseline Analysis, the nest hits a "zero-food" state around step 3,000, causing the population to plummet in a sharp, jagged crash. Because the LLM stockpiled food during its "Harvest Phase", its population decline remains gradual and managed. Even as resources dwindle, the LLM-governed colony remains stable, proving that strategic adaptability is the key to surviving the "long tail" of a resource-depleted environment.


Scenario 2: The Invasion
In Scenario 2, the system's resillience is tested by a hostile invasion. Starting at simulation step 1,000, a wave of 10 enemies spawns progressively (one every 100 steps). This scenario measures how the LLM-Governor handles a sudden, non-linear shift from a state of growth to a state of total defense.
The CHI and Pareto Frontier highlight a much more aggressive trade-off than in the default scenario.
The CHI Over Time shows that both strategies track closely until the invasion begins. Once the enemies arrive at step 1,000, unlike Scenario 1, the LLM does not establish a statistically significant CHI advantage under sustained pressure: the invasion load is severe enough that neither strategy clearly dominates on composite health.
The Pareto Frontier reveals the high cost of this stability:
-
The Baseline Mean (Blue Cross): Ends with a higher population (~73 survivors) but very low food security (~40 units).
-
The LLM Mean (Red Cross): Accepts a significantly lower terminal population (~62 survivors) to ensure nearly double the food reserves (~75 units).
In a high-threat environment, the LLM prioritizes colony-level survival (food) over individual-level survival (population), recognizing that a starving colony is more fragile than a small, well-fed one.

The Average Workforce Allocation and System Dynamics charts capture the exact moment the "Hive Mind" recognizes the crisis.
Between steps 0 and 1,000, the LLM optimizes for a "pre-emptive" harvest, spiking Resource Efficiency to ~0.20, roughly three times higher than the Baseline's peak of ~0.07, the one metric where LLM shows a statistically significant advantage in this scenario.
When the invasion triggers at step 1,000, the Workforce Allocation shows a massive, suddent pivot. The LLM slashes the forager count and spikes the Guardian ratio to over 80% to meet the threat. The Baseline, remaining locked at 50/50 heuristic, fails to adapt its labor to the new reality, resulting in a lower efficiency during the harvest and a weaker defense during the surge.


The final outcomes are seen in the Threat Analysis and Death Spiral.
Interestingly, the Threat Analysis shows that the Baseline actually achieves a higher cumulative kill count, reaching the full 10 kills, whereas the LLM median stabilizes slightly lower at ~9.6. This suggests that the LLM is not seeking to "win the war" at any cost; rather, it uses its Guardians to delay and deter, focusing on protecting the nest's core rather than engaging in high-risk combat that would further deplete the population.
This "defensive buffer" strategy prevents the catastrophic Death Spiral. In the Baseline scenario, food reserves drop to near-critical levels, leading to a jagged population decline. Under 15 total enemies, however, the pre-invasion food buffer is not sufficient to separate the LLM from the Baseline by simulation end. Both conditions show high variance and qualitatively similar outcomes, the sustained threat duration ultimately overwhelms the governance advantage.


Conclusion
This project demonstrates a practical implementation of a Hierarchical Complex Adaptive System, successfully bridging the gap between local emergence and global regulation. By decoupling tactical execution (RL) from strategic governance (LLM), the system overcame the inherent brittleness of static policies.
The experiments confirm that a Homeostatic Regulator is essential for survival in non-linear environments. While the baseline agents optimized for immediate rewards, the LLM-Governor successfully identified long-horizon risks, trading short-term population counts for long-term resource security. This mirrors biological systems, where the survival of the superorganism takes precedence over the individual.
The architecture developed here, Decentralized Autonomy with Strategic Governance, has implications far beyond a digital ant colony. The transition from "Harvest Phases" to "Defense Spikes" mirrors the challenges found in several real-world domains:
-
Supply Chain Logistics: Using local agents to optimize warehouse routing (Micro) while an LLM-Governor monitors global geopolitical "shocks" or weather patterns to pivot inventory strategy (Macro).
-
Smart Grid Management: Autonomous local substations managing load balancing (Micro) while a central regulator anticipates city-wide surges and redirects energy reserves to prevent a "Death Spiral" (Macro).
-
Robot Swarm Coordination: Directing search-and-rescue drones to prioritize individual battery life or collective area coverage based on the evolving urgency of the mission.
Ultimately, this architecture validates that hybrid intelligence, combining the fast, instinctive reactions of Neural Networks with the slow, deliberate reasoning of Large Language Models, is a viable blueprint for creating autonomous systems capable of surviving high-entropy environments.